ЧТО ЗА ХУЙНЯ?
Сейчас будет рассказано, как быстро и просто,без хуйни, построить структуру файлового носителя с системой NTFS и вытащить файлы.
hexedit –s <имя_файла>
первое что нам нужно - посмотреть на первые 4 строки вывода

записываем себе вот эти данные -

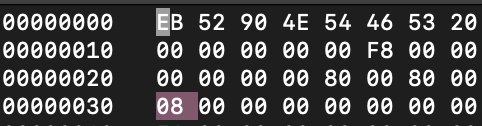
Далее - важно!
Допустим, будем называть вычисления далее перехуевертом
определим действие “перехуеверчивание” по правилу: был у нас 00 02 - стал 02 00, что равняется 200
(меняем местами)
следующим шагом нужно попасть на MFT - для этого складываем, пизжу, перемножаем все что мы запомнили выше - 20048 = 4000 и переходим по адресу 0x4000 (перед сложением(я пиздабол-не забывайте) - добавляем 0x(ноль x))
ебашим на 0x4000 - для этого умные люди(не мы) жмякают ctrl+g (плюс жмякать не надо)
Отсюда можно начинать поиск остальных файлов. Для этого мы скроллим нахуй на дикой скорости всю таблицу, пока не наткнемся на какую-то значащую запись. Чтобы понять, что мы не на служебной записи – обращаем внимание на содержимое справа. Например, у мфт есть обозначение $MFT. В других записях есть другие обозначения (например $LogFile). Это нам все нахуй не надо, мы ищем нормальную запись. Пустые тоже к хуям. Поскроллив 3 часа (ну или пару секунд, если вы не долбоеб, не знающий о кнопке page down) и мы, наконец, находим первую запись.
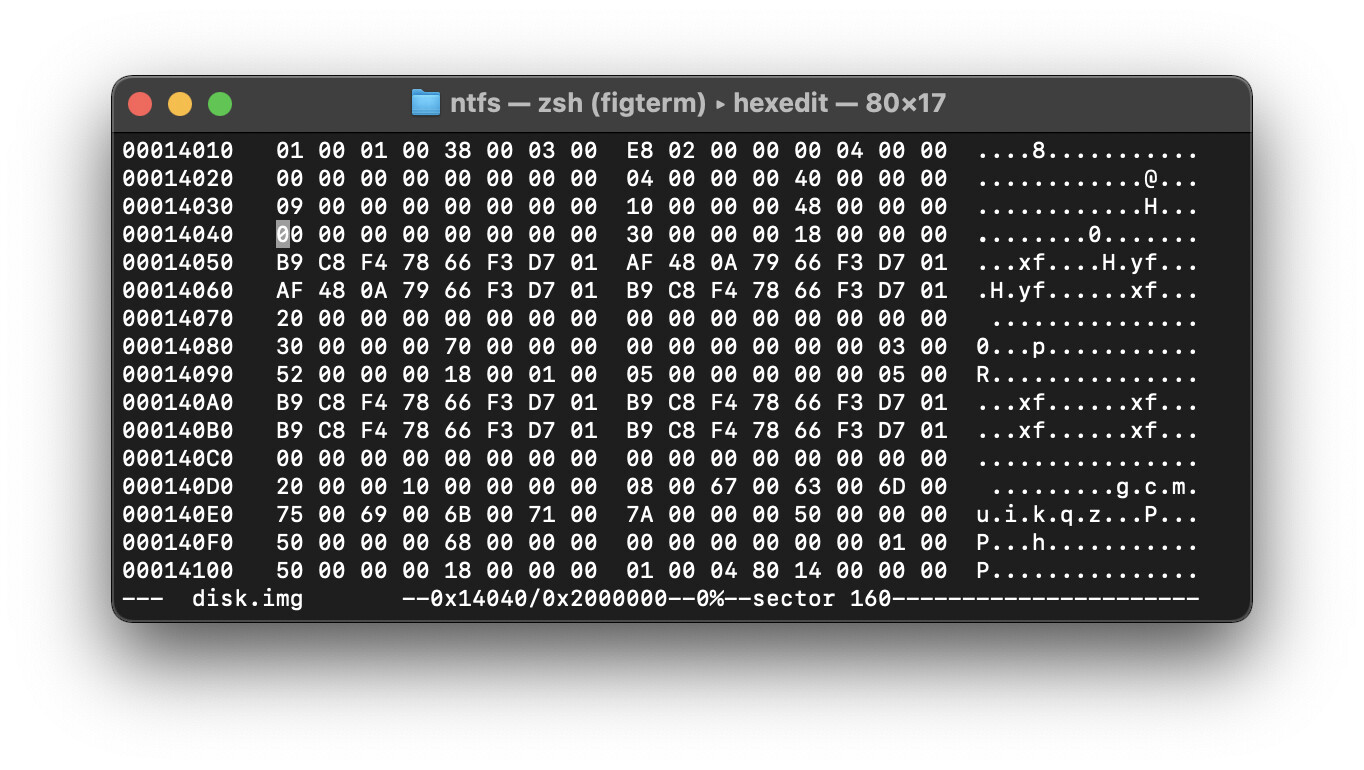
далее нам нужно сделать следующую непонятную хуйню(часть хуйни объясню, часть так и останется поебенью)
hexdump -C -n $((0x100)) -s $((<смещение>)) <имя_файла>
В данной команде мы выводим значения по 0х100 элементов, начиная с нужного смещения. Например, для случая на скриншоте, значение <смещение> будет составлять 0х14000. Имя файла - имя образа который мы трахаем
выполняем команду
выглядеть она будет так -
hexdump -C -n $((0x100)) -s $((<с0x14000>)) <имя_файла>
запоминаем вот эту хероебину
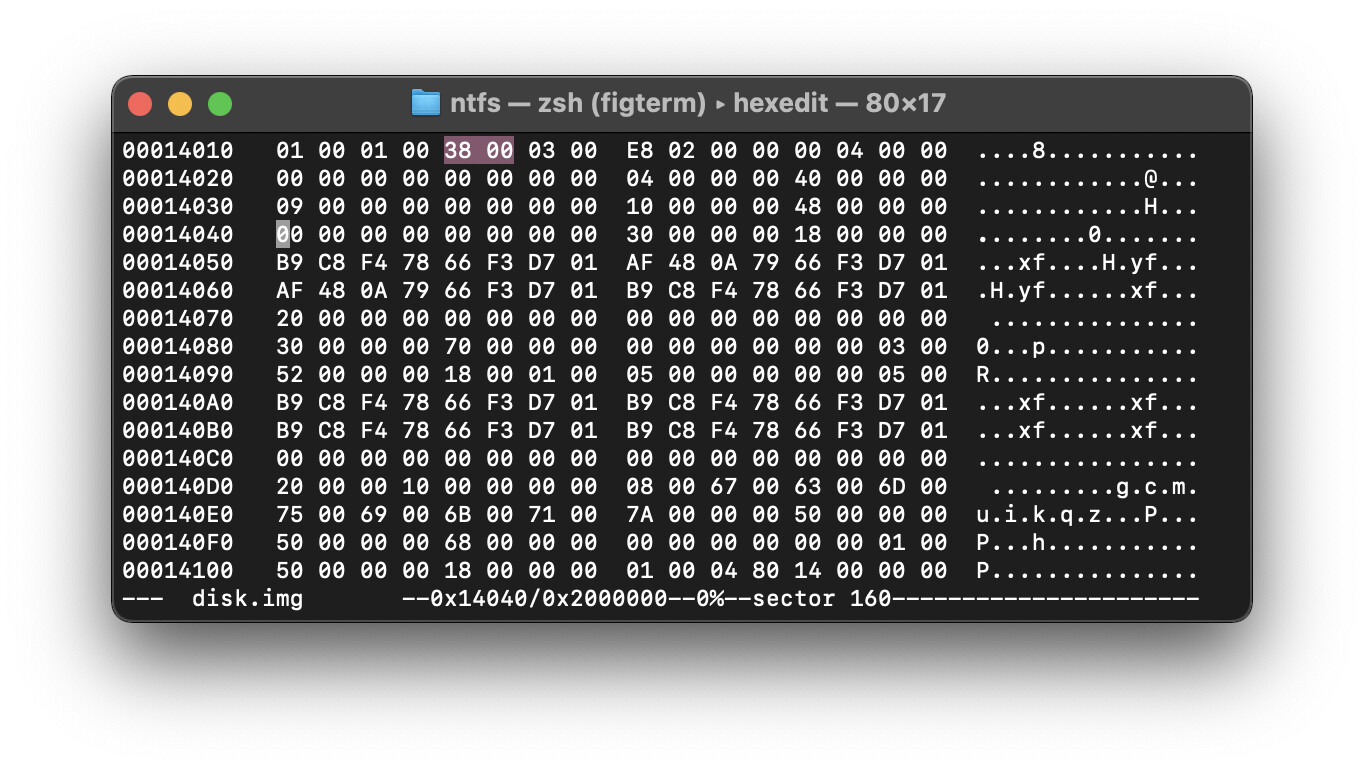
выполняем теперь такую команду (я сам не особо понимаю че там за флаги такие, так что поооооохуй - так надо. меньше знаешь - крепче спишь (не забывайте - я пиздабол)
hexdump -C -n $((0x100)) -s $((<смещение>+0х38)) <имя>
дальше смотрим и ахуеваем, тк нихуя не поменялось, НО НИХУЯ - ПОМЕНЯЛОСЬ.
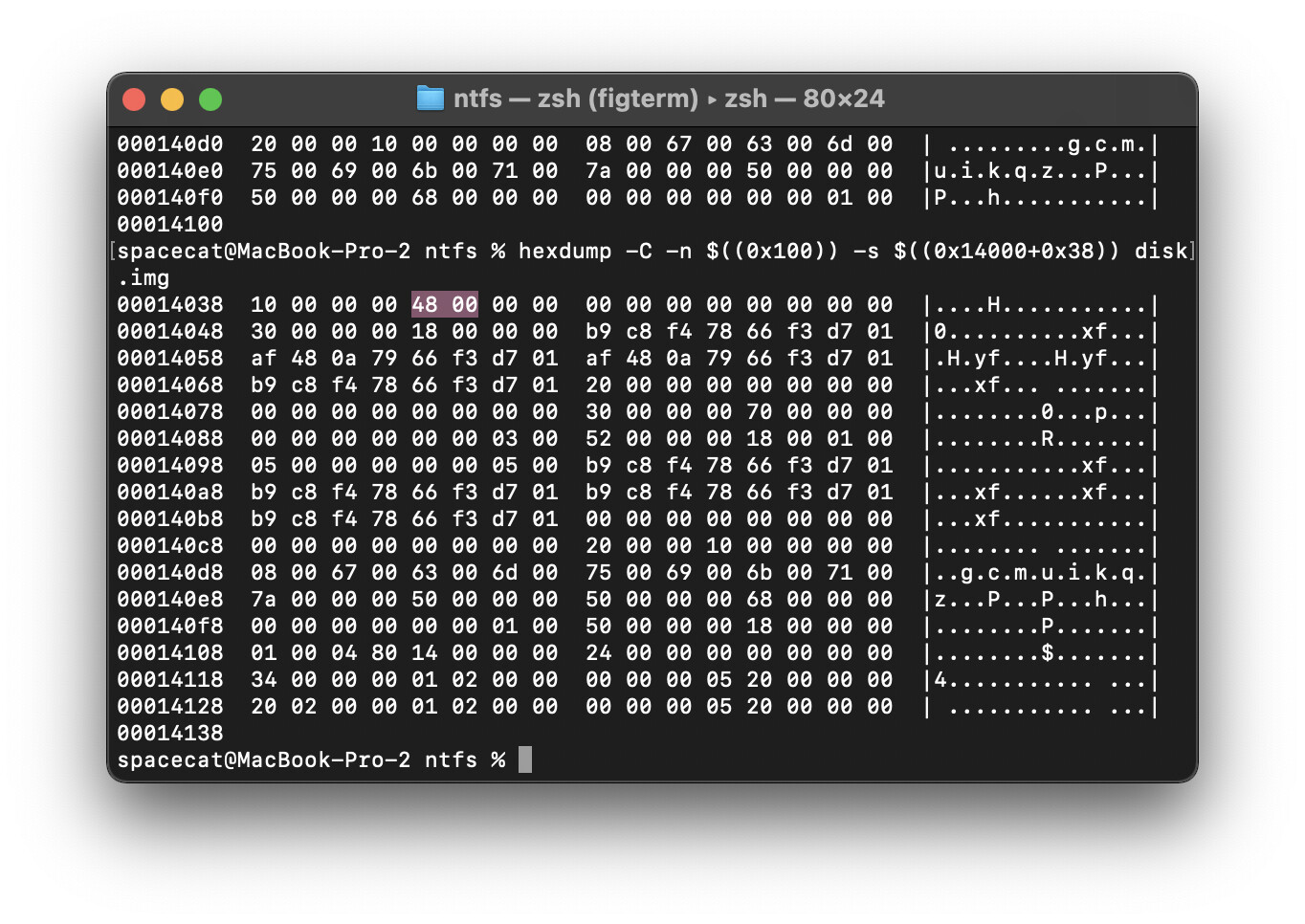
хуярим эту поеботу в эту пиздорину
hexdump -C -n $((0x100)) -s $((<смещение>+0х38+0х48)) <имя>
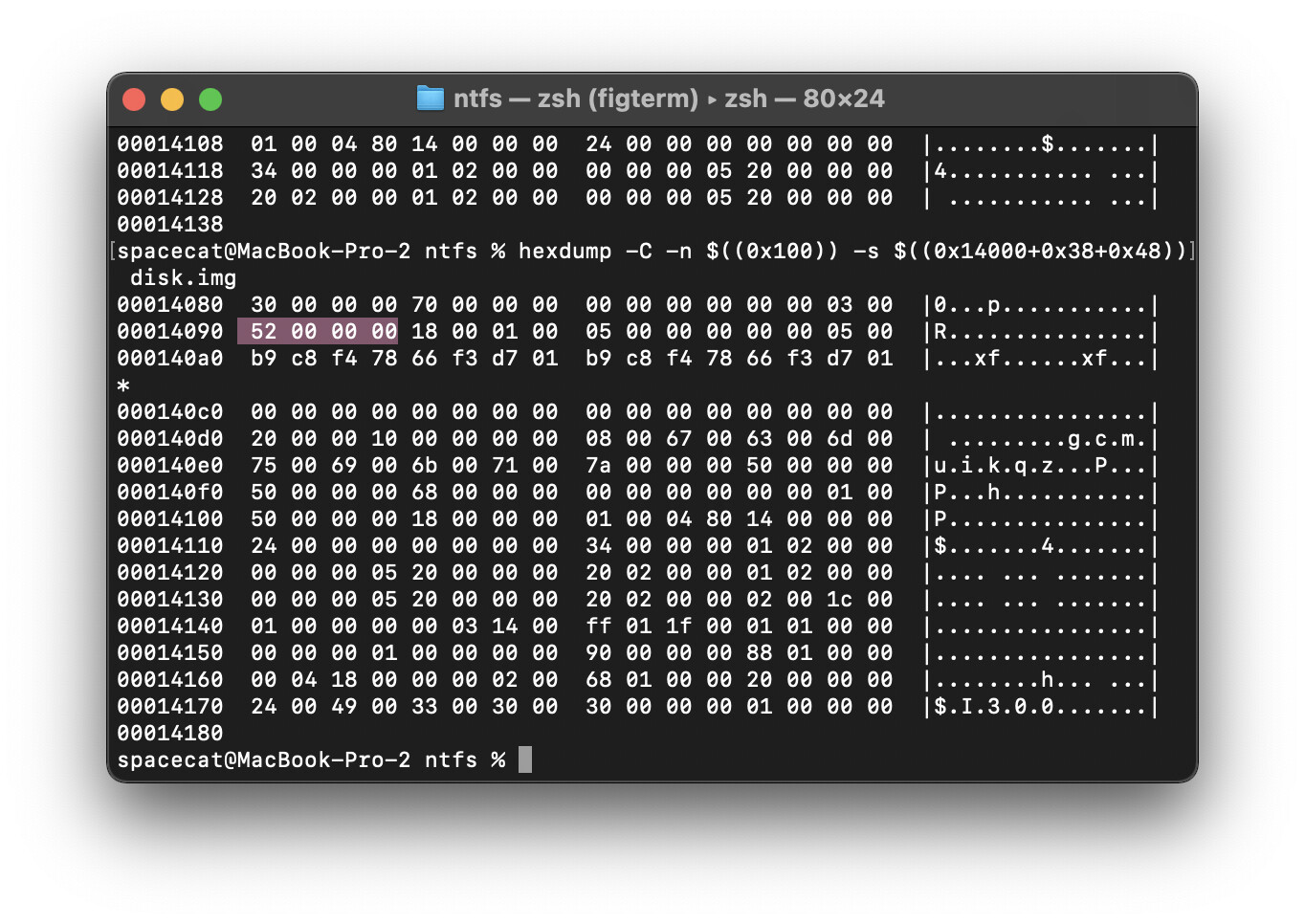
название первого искомого мы видим

крч. записываем эту хуйню
далее, чтоб построить дерево просто херачим +0x80 пока не отвалится член(не кончатся записи и не пойдут пустые файлы) (ЗАПИСЫВАЕМ ВСЮ ПОЕБОТУ ЧТО НАЙДЕМ С АДРЕСАМИ ЧТОБ ПОТОМ НЕ АХУЕВАТЬ ОТ ЖИЗНИ)
(пример неебического поиска файла) -
hexdump -C -n $((0x100)) -s $((<смещение>+0х38+0х48+0x80+0x80+0x80+0x80)) <имя>
как ток кончилось - идем в хексэдит и скроллим снова с менее ахуенной скоростью но не проебываясь дальше до следующего файла и повторяем процедуру(да, это геморно, ну а хули ты хотел?) (команда для открытия хексэдита ниже, не ссы)
hexedit –s <имя_файла>
Все нашли - заебок
следующий пункт
КАК ДОСТАТЬ ЭТУ ПОЕБОТУ БЛЯТЬ?
Вводим ад ручного ввода
dd if=<имя>.img of=<имяфайла> bs=1 skip=$((смещение_hex)) count=$((размер_hex))
пояснять я это конечно же не буду, ток в of - расширение на файле не ставьте - в пизду - не сохранится нихуя, а в if - файл который мы смотрим(образ диска)
кароч, расскажу че делать с этой хуйней
во первых надо перекурить…
в идеале нахуй это все…(стр 9 пункт 1 оригинальной методички)

кароч
имя файла запомнили - еще надо глянуть - а че там внутри - для этого снова скролит на скорости дрочки это все в хексэдите пока не найдет нужное нам имя файла (если внутри файла другой файл - все хуйня, давай по новой - это каталог - его искать не надо)
находим файл
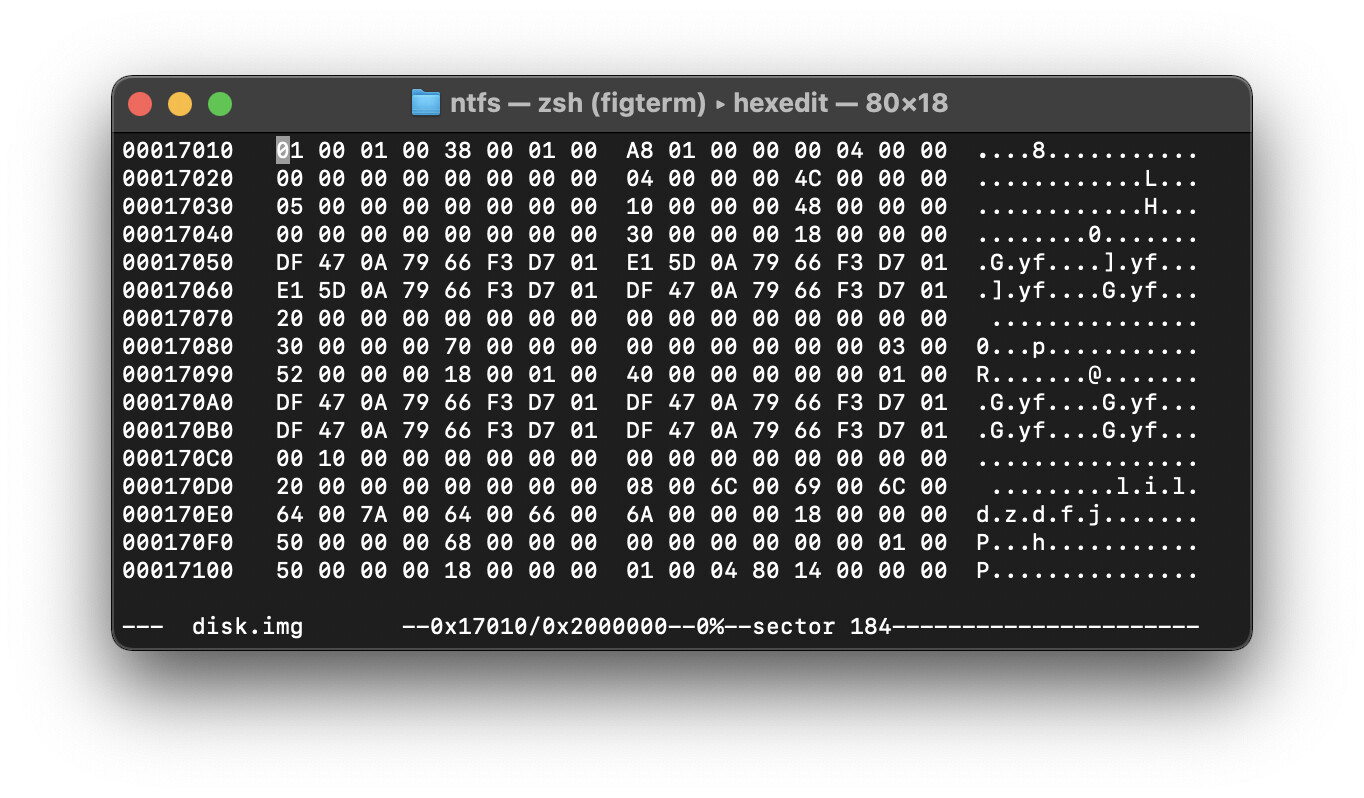
заебок - теперь во втором столбике большом (по скрину ориентируемся, епта) ищем 40 (первые две цифры во втором столбике - еще раз повторяю бана в рот, сразу не понятно чтоль?!)
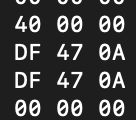
нашли - пошли нахуй
это говно не подходит, так как под 40 находятся две DF. надо чтоб различалось. кароч два одинаковых значения = идем нахуй и ищем еще 40 (мб придется пролистать пониже - главное в глаза не долбитесь)
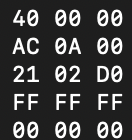
находим
смори ебать - вот повторяю дд
dd if=<имя>.img of=<имяфайла> bs=1 skip=$((смещение_hex)) count=$((размер_hex))
по нам надо - если у нас
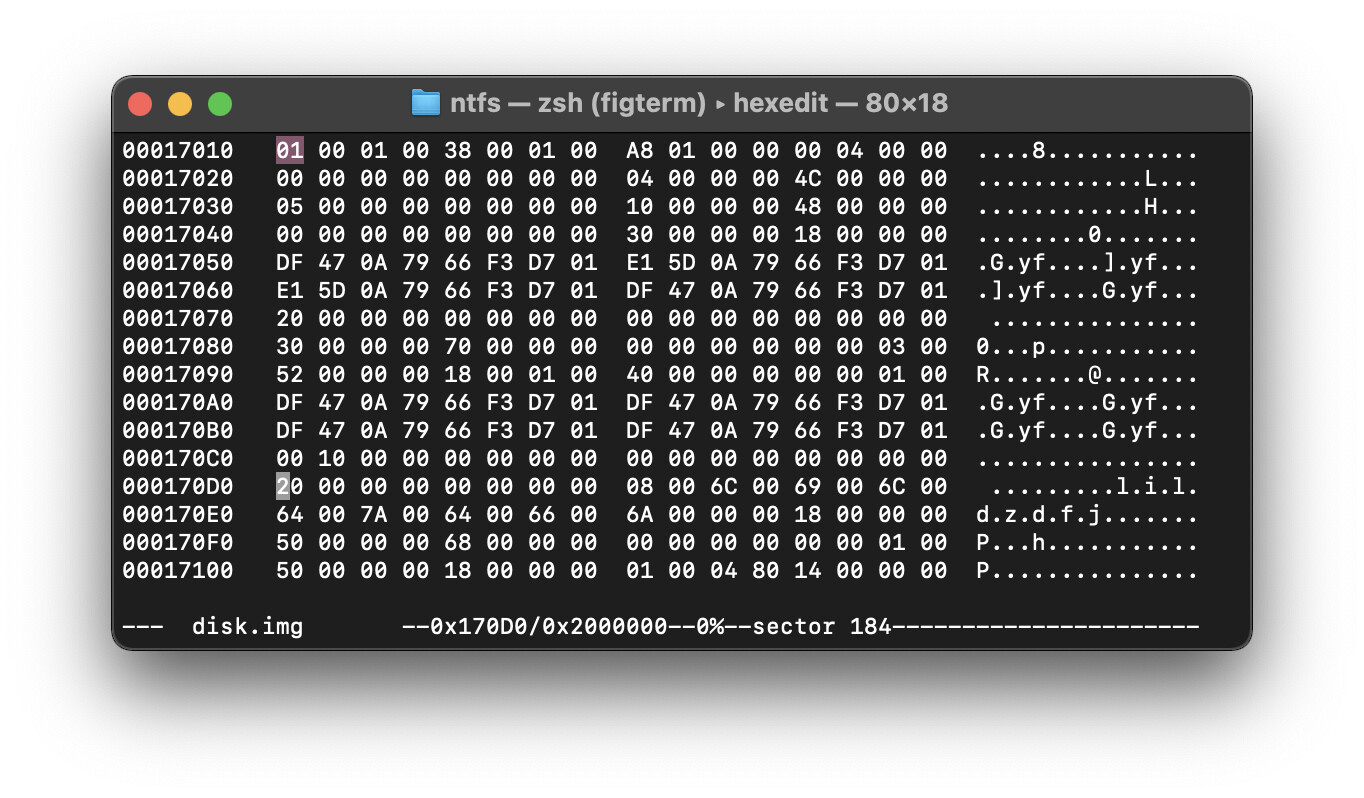
вот тут стоит 1 (после FILE0 в листинге первая строка) - смотрим вот тут
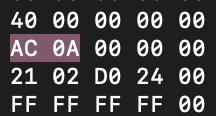
эта хуйня нам нужна. ее мы перехуеверчиваем по правилу описанному выше и добавляем в <<смещение>> не забыв 0x (ноль икс, а не ох ах тут тебя ебут но не так)
если единички нет - пропускаем в пизду это count - меньше гемора(хаха, я опять напиздел)
далее -
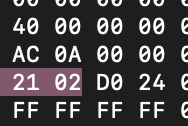
смотрим на эту парашу
видим 21 02. непонятная хуйня, но 02 - это то, сколько столбиков по два символа нам нужно перехуевертить в следующий раз
два - значит два. один - значит один. три - ну пизда - значит три… не путать, блеять
кароч у нас 2. заебок.
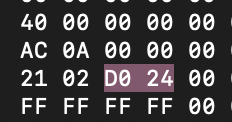
вот эти два символа перехуеверчиваем. запоминаем (0x не забыл, сука?)
далее вспоминаем что мы забыли уже, но записали (ищи в начале статьи размер сектора и число секторов). дальше перехуеверченные значение перемножаем добавляем в команду вместе с перехуеверченная хуйней номер 2 (слава коньяку можно перемножить прям в команде)
итоговая команда нахуй будет выглядеть так
dd if=<имя>.img of=<имя файла> bs=1 skip=$((перехуеверченный размер сектора*число секторов(не хуевертим его)*перехуеверченная хуйня номер 2)) count=$((перехуеверченная хуйня номер 1))
в нашем случае
dd if=disk.img of=fuck bs=1 skip=$((0x200*0x4*0x24D0)) count=$((0x0ААС))
выполняем эту команду в терминале(типа до этого мы были в World of Tanks, да)
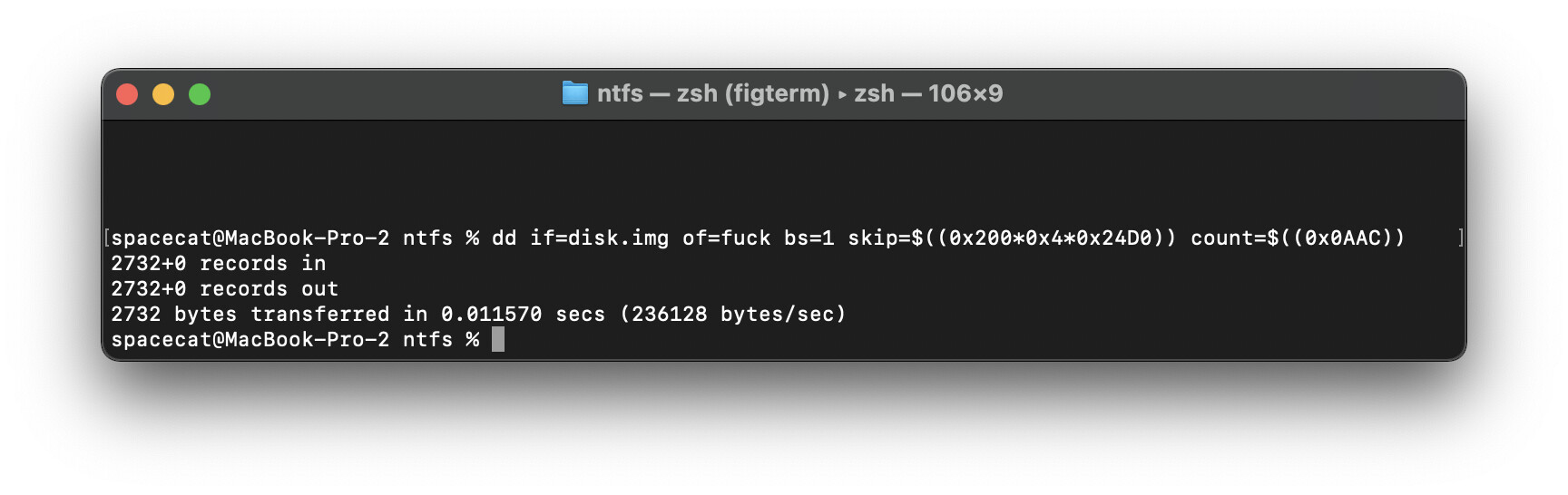
делаем так для всех файлов найденных - дрочилово адское
Считаем md5 сумму
md5sum <имя файла>
в нашем случае
md5sum fuck
я буржуй ебаный - скрин с мака - команда чуть другая. суть та же
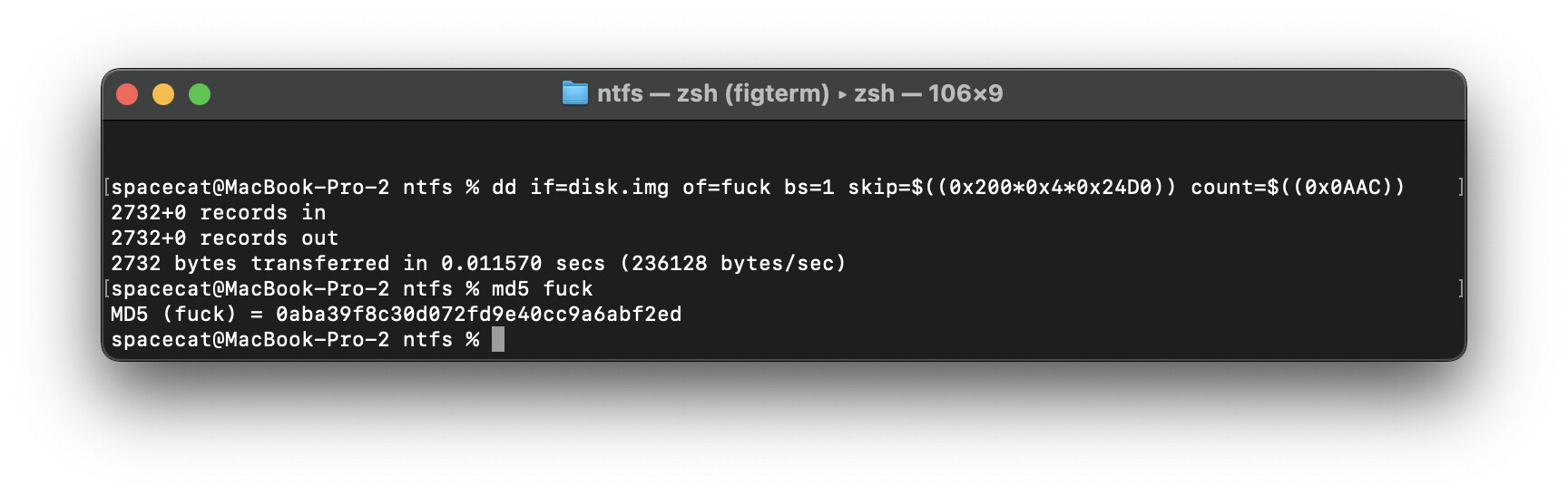
ПОЗДРАВЛЯЮ - МОЖНО ИДТИ КУРИТЬ БАМБУК И БЕЗ ЗАЗРЕНИЯ СОВЕСТИ ПОЗВОЛИТЬ СЕБЕ СТРАНИЦА 9 ПУНКТ 1 ОРИГИНАЛЬНОЙ МЕТОДИЧКИ
